Microservice has been a hot new concept in these days. Martin Fowler explained microservice in this article. From me, microservice is a set of fine-grained function units running on independent process, each of them are connected with light-weighted transports: RESTful API or light messaging queue.
It's a new concept in enterprise architecture, since the last movement in the field promotes SOA architecture. SOA encourages architects to componentize their business logic in service, and deploy service bus(ESB) for integration. Microservice can be more concrete and light-weighted. The service units in Microservice can be any standalone function, or just a tier in traditional tier based development. These units can be deployed on dedicate process or grouped into a process.
In clojure development at avoscloud, we are using the slacker cluster framework for our microsrvice architecture.
Slacker RPC exposes services as clojure namespace (pretty light-weighted) All functions in the namespace can be called from remote. A slacker server can expose any number of namespaces:
(start-slacker-server 2014 [my.serviceA my.serviceB ...])
Slacker uses a binary protocol on TCP and configurable serialization (json/edn/nippy) for communication, which is fast and compact.
And in slacker cluster, exposed namespaces are registered on zookeeper as ephemeral nodes. The client doesn't have to know which service is deployed on which process. Instead, it connects to zookeeper and look up all process address for service it interests in.
(def sc (clustered-slacker-client zk-addr ...))
(defn-remote 'sc my.serviceA/fn-abc)
;;when calling remote function for the first time, the client will look up zookeeper for remote processes and cache the results
(fn-abc)
If there are more than one process available, the client library will balance the load on each process. And for stateful service, slacker cluster also elects master node to ensure all requests go to single process. (Slacker cluster grouping)
Zookeeper directory structure:
ls /slacker/example-cluster/namespaces/
[my.serviceA, my.serviceB]
ls /slacker/example-cluster/namespaces/my.serviceA
[192.168.1.100:2104, 192.168.1.101:2014...]
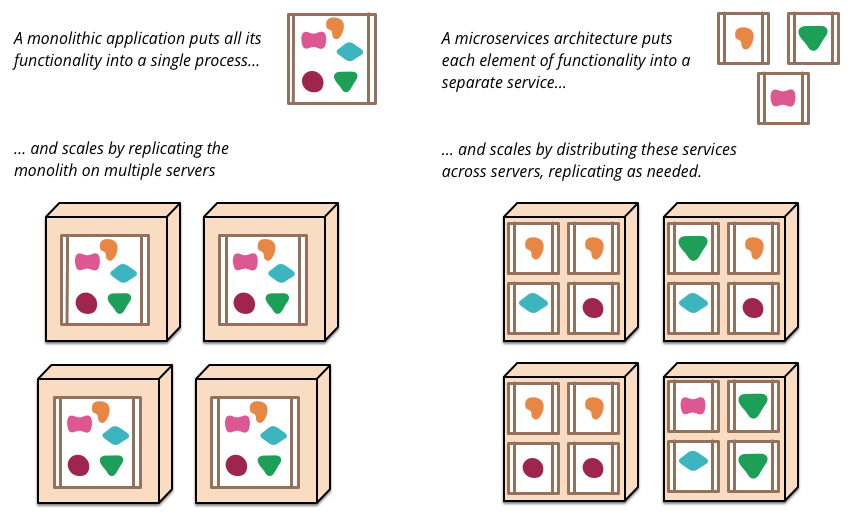
Decoupling processes and services made microservice deployment quite flexible. Functional namespaces can be deployed on any process, standalone or grouped together, like Martin Fowler's chart shows.
{kind=link}
All these nodes are also watched by clients. If a process crashed or put offline, the clients will get notified by zookeeper, then no requests will be made on that process. Also, when you exhausted service capacity, just simply put on another process, the client will soon balance load to the new node. Scaling services is easy like that.
Thanks to zookeeper's watch mechanism, there's no need to configure service static and update while you add/remove nodes. This is especially important in large-scale deployment. (Since microservices are often find-grained, you will always have a lot of process to update/restart.)
For more about Slacker Cluster, check my code repository.